



Beware of Throttling Issues when you build large scale applications Having Data Science and Big Data Analytics Use Cases, Our Experience to see this
During my Consulting work in a UK company, I had to involve in working with one of the large monolithic JEE application (Java Web) which was built and operational for last 10 years and they said me to look at the performance issues which they were trying to fix.
- Application Features:
- One of the larget that kind in the world:
- Half a TB Data in Relational Data Base
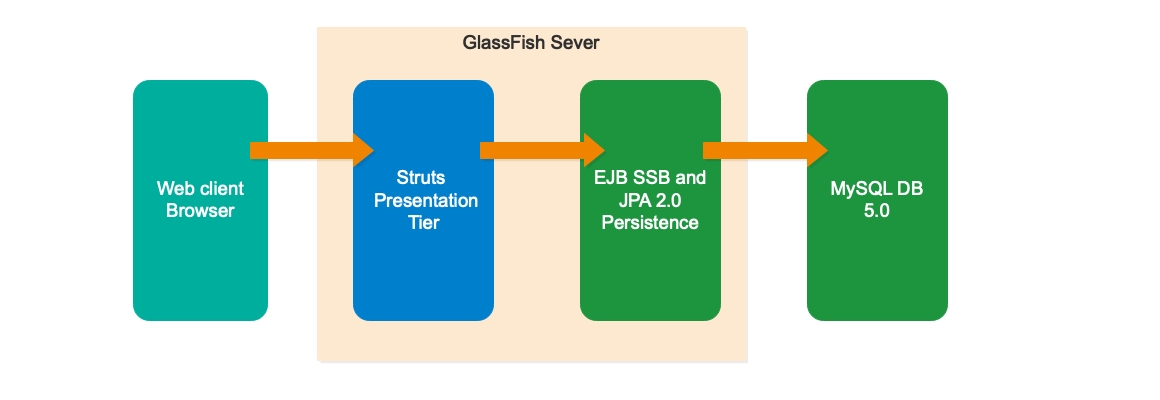
- Built With EJBs in the Business Tier JPA 2.0 Spec with Entity Managers
- Struts in the Experience Layer which generate view
- Glass Fish server
- Linux CentOS, JDK 8
Issues with the Application:
-
Aacdemically Inspiring Issues and facts: - Application had several common issues but one thing that I was inspired in align with my academic and reseach mind was the throtlling issue experienced in the request processing layer of the application. With the Glashfish server they were struggling to achive stateful clustering. That brought some load balancing incapabilities. Due to this load balancing abscense they vertically scaled the hardware for the application into several hundred of GBs RAM !! And also they configured to handle couple of thousands of request processing threads as a thread-pool configuration in the Glashfish server. The interesting fact was that, even with this large amount of thread pool configured at app server, the requests again were queued up in the processing queue. Those queued up requests were not getting threads allocated and finally got timed-out.
-
Past debugging and fixes they tried before I was engaged: - A consulting company checked the hardware, network and software components. They tried changing A Linux Kernel level flag to increase the bandwith traffic from Application Server to DB Server. In fact the performance issues like blank pages and timeouts would have slightly improved if the development/deployment team could figure out how it can be clustered. Unfortuately that was also a fact that, the application was not cluster ready nor stateless to just put some simple reverse proxies. To change the application to stateless mode was a impossible issue, as there has to change the code and architecture and thus re-write the application. Yeah that was a fact and we did it.
- To support the demanding number of concurrent users and the corresponding load they beefed up the hardware vertically. I could see several hundred of GBs RAM and 100s of CPU cores on every a single Bare metal servers. Yeah that is true they had issues with cloud as well. What I can imagine, if they split that into a few servers say six with new generation architecture with using half of the total hardware, they would have even achieved 10 times performance boost (my gut feeling)! Even some UK companies does have that issue! Oh man/Gal we are really better in India compared to many of the IT companies around the world.
-
How would be system working then!
- If we roughly calculate say around 8 threads can safely execute on a core the maximum threads that can execute on app server will be around 800. When a couple of hundreds of web requests comes to the server that could have really processed them well. Yeah, that was case, but only for first a few hours. After a few hours of data processing time application started hanging, blank page and timeout started creep-in to frustate the end users.
Yeah, I agree. Even with the best and large amount of hardware and cutting edge technical softwares people can develop and host horrible systems! Gireesh Babu, Expertzlab Technologies Pvt. Ltd.
My Investigations to find out the root cuases:
- Blogs from Database!! Can you imaginge, the customer interactions and their texts were stored in DB!! There were a lot of Text Seraches to hit Databases which causes a hell lot of processing shoot ups. I would consider, would have suggested, a search engine to index, and that would have better to map customer details and organise them. Yeah even Telecom companies do that!
- Some Queries which are frequently executed took more than a 100 Sec, sometimes due to unreasonable number of table joins. There were millions of rows of data and then, You can imagine how it will be in joing those tables, that too more than 7 levels in a single query, ummm, it is definitely unreasonable. you can imagine the number of records after cross product "million X million X million .... 7 times" no doubt how much time it will take the DB to complete that seach/table scan and bring a result from for that query.
- Transactions executed against DB took long time especially after a few hour of execution and then resources won't be freed as the transaction time-out happens. There are a very high amount of threads waiting for the DB connections to get them sloted to be executed. That means DB connection pools exhosted, and no new threads in the pool available for connecton and query execution. Entire request processing threads in the application were blocked for some time, subsequently every requests. This was the primary reason for request queued up in the processing layer.
What was the Solution?
We also adopted NodeJS frontend processing layer (reactive systems and programming) and adopted Angular SOFEA style frontend. We found Angular much more decent than ReactJS as Angular brought very decent level of code level organisation and conventions to the project where even beginners could contribute to the UI layer development.
The incremental data processing minimised the final issues at running batched scheduled at daily, week-end and monthly etc processing them using Flink. It was very instrumental to execute that work load using Flink and used askaban as scheduling engine. The request processing layer were Docker containerised and depoyed in cloud using Kubernetes and later Service Mesh. There was an initial learning curve, however once the right tool and enough scripts were adopted, everything felt much more easier than imagined.
We had initial inhibitions to adopt microservice achitecture and MongoDB NoSQL for such a highly complicated transactional system. Many of the team memebers were skeptical to replace RDBMS with MongoDB. Such a level of abscence of relational table joins were difficult to imagine initially. However when more and more caches and object level managements than query level was adopted and instrumental, then we found system was very robust in terms of performance.
Conclusions:
Now, we are so happy that we took right decisions and there were right partners/trainers which was key. It will be also interesting to know the detailed architecture. I have a plan to write about the application architecture that we used for replacement. I can update this space shortly, watch this place for updates.
